



mindspore掌中宝是依靠功能强大的ai计算框架,不仅在学术上有着巨大的作用,也能满足工业方面的性能需求,支持照片检测、代码分享、场景识别等诸多功能,对于开发者而言此软件也极为实用,极大提升了编程的效率,让用户可在短时间内完成调试及部署等操作。
软件功能
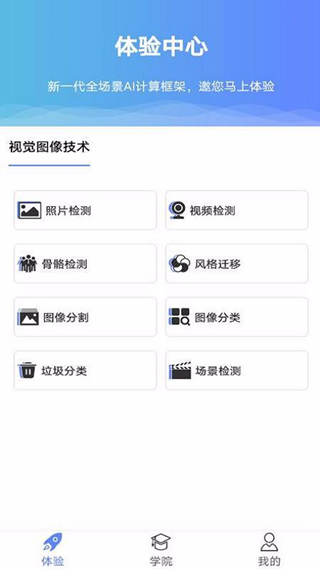
1、识别垃圾类别,通过垃圾分类功能可以利用相机检测识别垃圾的类别;
2、检测场景范围状况,使用场景检测功能扫描识别当前的场景并获取参数信息;
3、照片经检测识别,点击照片检测即可马上打开照片并查看其中的各种检测元素;
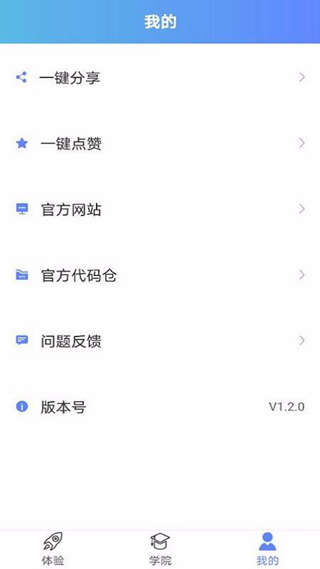
4、给该软件点赞,能在我的主页选择点赞功能并根据自己的使用体验给软件点赞;
5、将软件分享给自己的好友,选择并点击一键分享功能即可将软件分享;
6、查询代码资源,进入到官方代码仓中就能从中查找需要的代码内容资源;

软件特色
极致性能
高效的内核算法和汇编级优化,支持CPU、GPU、NPU异构调度,最大化发挥硬件算力,最小化推理时延和功耗。
轻量化
提供超轻量的解决方案,支持模型量化压缩,模型更小跑得更快,使能AI模型极限环境下的部署执行。
全场景支持
支持iOS、Android等手机操作系统以及LiteOS嵌入式操作系统,支持手机、大屏、平板、IoT等各种智能设备上的AI应用。
高效部署
支持MindSpore/TensorFlow Lite/Caffe/Onnx模型,提供模型压缩、数据处理等能力,统一训练和推理IR,方便用户快速部署。
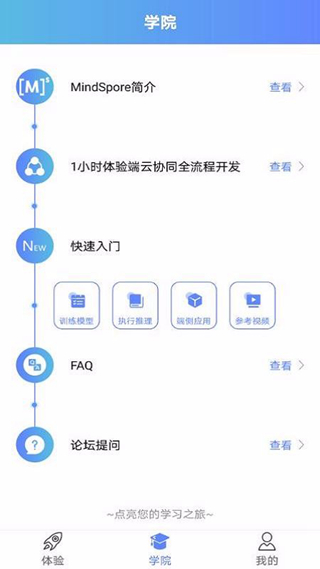
快速入门
通过一个实际样例实现手写数字的识别,带领大家体验MindSpore基础的功能,一般来说,完成整个样例实践会持续20~30分钟。
情感分析
构建一个自然语言处理的模型,通过文本分析和推理实现情感分析,完成对文本的情感分类。
图像分类
结合CIFAR-10数据集,讲解MindSpore如何处理图像分类任务。
识别猫狗APP
在PC上对预训练模型进行重训,在手机终端完成推理和部署,1小时内体验MindSpore端边云全场景开发流程。
适用场景
图像分类
您可以使用预制图像分类模型,识别摄像头输入帧中的物体。
目标检测
您可以使用预置目标检测模型,检测标识摄像头输入帧中的对象并添加标签,并用边框标识出来。
图像分割
图像分割可用于检测目标在图片中的位置或者图片中某一像素是输入何种对象的。
加载图像数据集
准备
导入模块
该模块提供API以加载和处理数据集。
import mindspore.dataset as ds
下载所需数据集
运行以下命令来下载MNIST数据集的训练图像和标签并解压,存放在./datasets/MNIST_Data路径中,目录结构如下:
!unzip -o MNIST_Data.zip -d ./datasets
!tree ./datasets/MNIST_Data/
./datasets/MNIST_Data/
├── test
│ ├── t10k-images-idx3-ubyte
│ └── t10k-labels-idx1-ubyte
└── train
├── train-images-idx3-ubyte
└── train-labels-idx1-ubyte
2 directories, 4 files
加载数据集
MindSpore目前支持加载图像领域常用的经典数据集和多种数据存储格式下的数据集,用户也可以通过构建自定义数据集类实现自定义方式的数据加载。
下面演示使用mindspore.dataset模块中的MnistDataset类加载MNIST训练数据集。
1.配置数据集目录,创建MNIST数据集对象。
DATA_DIR = './datasets/MNIST_Data/train'
mnist_dataset = ds.MnistDataset(DATA_DIR, num_samples=6, shuffle=False)
2.创建字典迭代器,通过迭代器获取一条数据,并将数据进行可视化。
import matplotlib.pyplot as plt
mnist_it = mnist_dataset.create_dict_iterator()
data = next(mnist_it)
plt.imshow(data['image'].asnumpy().squeeze(), cmap=plt.cm.gray)
plt.title(data['label'].asnumpy(), fontsize=20)
plt.show()
../_images/use_load_dataset_image_16_0.png
此外,用户还可以在数据集加载时传入sampler参数用来指定数据采样方式。MindSpore目前支持的数据采样器及其详细使用方法,可参考编程指南中采样器章节。
数据处理
下面演示构建pipeline,对MNIST数据集进行shuffle、batch、repeat等操作。
操作前的数据如下:
for data in mnist_dataset.create_dict_iterator():
print(data['label'])
5
0
4
1
9
2
1.对数据进行混洗。
ds.config.set_seed(58)
ds1 = mnist_dataset.shuffle(buffer_size=6)
print('after shuffle: ')
for data in ds1.create_dict_iterator():
print(data['label'])
after shuffle:
4
2
1
0
5
9
2.对数据进行分批。
ds2 = ds1.batch(batch_size=2)
print('after batch: ')
for data in ds2.create_dict_iterator():
print(data['label'])
after batch:
[4 2]
[1 0]
[5 9]
3.对pipeline操作进行重复。
ds3 = ds2.repeat(count=2)
print('after repeat: ')
for data in ds3.create_dict_iterator():
print(data['label'])
after repeat:
[4 2]
[1 0]
[5 9]
[2 4]
[0 9]
[1 5]
可以看到,数据集被扩充成两份,且第二份数据的顺序与第一份不同。
说明:
因为repeat将对整个数据处理pipeline中已经定义的操作进行重复,而不是单纯将此刻的数据进行复制,故第二份数据执行shuffle后与第一份数据顺序不同。
数据增强
下面演示使用c_transforms模块对MNIST数据集进行数据增强。
1.导入相关模块,重新加载数据集。
from mindspore.dataset.vision import Inter
import mindspore.dataset.vision.c_transforms as transforms
mnist_dataset = ds.MnistDataset(DATA_DIR, num_samples=6, shuffle=False)
2.定义数据增强算子,对数据集执行Resize和RandomCrop操作。
resize_op = transforms.Resize(size=(200,200), interpolation=Inter.LINEAR)
crop_op = transforms.RandomCrop(150)
transforms_list = [resize_op, crop_op]
ds4 = mnist_dataset.map(operations=transforms_list,input_columns='image')
3.查看数据增强效果。
mnist_it = ds4.create_dict_iterator()
data = next(mnist_it)
plt.imshow(data['image'].asnumpy().squeeze(), cmap=plt.cm.gray)
plt.title(data['label'].asnumpy(), fontsize=20)
plt.show()
加载文本数据集
准备
1.准备文本数据如下。
Welcome to Beijing!
北京欢迎您!
我喜欢English!
2.创建tokenizer.txt文件并复制文本数据到该文件中,将该文件存放在./test路径中,目录结构如下。
└─test
└─tokenizer.txt
3.导入mindspore.dataset和mindspore.dataset.text模块。
import mindspore.dataset as ds
import mindspore.dataset.text as text
加载数据集
MindSpore目前支持加载文本领域常用的经典数据集和多种数据存储格式下的数据集,用户也可以通过构建自定义数据集类实现自定义方式的数据加载。
下面演示使用mindspore.dataset中的TextFileDataset类加载数据集。
1.配置数据集目录,创建数据集对象。
DATA_FILE = "./test/tokenizer.txt"
dataset = ds.TextFileDataset(DATA_FILE, shuffle=False)
2.创建迭代器,通过迭代器获取数据。
for data in dataset.create_dict_iterator(output_numpy=True):
print(text.to_str(data['text']))
获取到分词前的数据:
Welcome to Beijing!
北京欢迎您!
我喜欢English!
数据处理
MindSpore目前支持的数据处理算子及其详细使用方法,可参考编程指南中数据处理章节。
下面演示构建pipeline,对文本数据集进行混洗和文本替换操作。
1.对数据集进行混洗。
ds.config.set_seed(58)
dataset = dataset.shuffle(buffer_size=3)
for data in dataset.create_dict_iterator(output_numpy=True):
print(text.to_str(data['text']))
输出结果如下:
我喜欢English!
Welcome to Beijing!
北京欢迎您!
2.对数据集进行文本替换。
replace_op1 = text.RegexReplace("Beijing", "Shanghai")
replace_op2 = text.RegexReplace("北京", "上海")
dataset = dataset.map(operations=[replace_op1, replace_op2])
for data in dataset.create_dict_iterator(output_numpy=True):
print(text.to_str(data['text']))
输出结果如下:
我喜欢English!
Welcome to Shanghai!
上海欢迎您!
数据分词
MindSpore目前支持的数据分词算子及其详细使用方法,可参考编程指南中分词器章节。
下面演示使用WhitespaceTokenizer分词器来分词,该分词是按照空格来进行分词。
1.创建tokenizer。
tokenizer = text.WhitespaceTokenizer()
2.执行操作tokenizer。
dataset = dataset.map(operations=tokenizer)
3.创建迭代器,通过迭代器获取数据。
for data in dataset.create_dict_iterator(output_numpy=True):
print(text.to_str(data['text']).tolist())
获取到分词后的数据:
['我喜欢English!']
['Welcome', 'to', 'Shanghai!']
['上海欢迎您!']
特别说明
软件信息
- 包名:com.mindspore.himindspore
- MD5:8EF306168B5F6588A082C9E8612B1209

 QPython
QPython
 QPython OH
QPython OH
 结绳手册
结绳手册
 Dxapp
Dxapp












 讯飞语记app
讯飞语记app
 List背单词
List背单词
 好分数家长版
好分数家长版
 魔法人形师专业破解版
魔法人形师专业破解版
 艺术升
艺术升
 书小童
书小童
 TeamViewer 15
TeamViewer 15
 七天网络查分数软件
七天网络查分数软件
 掌门少儿APP
掌门少儿APP